Version 1.5 Preview
... About 4 min
# Commandeer Version 1.5 Preview
In our next installment of Commandeer, we are doubling down on our data focus. If you have been following along with what Commandeer is doing, we are focusing on three key aspects of your system, one of these pillars is Viewing your Data. In order to produce great things in the cloud, you need to be able to see what you are doing.
At Commandeer, we are dog-fooding our own tools all the time. Our backend analytics system is one of these things. We ingest data for analytics into DynamoDB via AppSync. We then have Dynamo Streams on those tables that are connected to lambdas to save this data to S3 in a data lake format so that we can query our data in Athena. As we have been building this, we are using AWS Glue crawlers to run against both DynamoDB and S3 to create tables for Athena. In order to facilitate this we have been working hard on getting the UI setup so that we can see what we are doing from all angles of the system.
# Team Management
To manage teams in Commandeer, you would go to Commandeer --> Teams ---> Dashboard. As we are expanding on this offering, and because of the fact that it is normally an engineering manager managing this aspect of the system, we are moving this to our web portal. Stay tuned over the next few releases as we will be rolling out resource, user, and tag statistics for you to better understand actual usage by your team within your system.
# AppSync
We are framing out the AppSync service. For those of you that are unfamiliar with AppSync, it is the GraphQL system offered by AWS. Those of you may remember Scaffold.io, which was a GraphQL tool. The developer of it was aqui-hired by AWS and brought in to build out AppSync. The first version was released about two years ago. A little later, Bill Fine, who was formerly a VP at Serverless Framework was brought in to head the business unit. I am excited to see what they show at re:invent this year.
Personally, I have mixed feeling about GraphQL. It does offer some cool pieces of functionality, and does make it more about the frontend developer than is the case with standard REST. But, setting it up, is certainly not trivial, and the templating engine is pretty crazy. So, we at Commandeer are working hard to try to make sense of all the functionality, and get it into a UI that helps manage it a bit better.
In this first incarnation, we will be releasing the general layout of AppSync, which consists of Data Source, Functions, and Resolvers. We will then rollout the Query Runner as well, which we think will be a very powerful way to test running queries of your data. Below you can see the high-level dashboard for AppSync.

AppSync Dashboard
The navigation is coming together nicely. Below you can see the different pieces of the system broken down on the left-hand side.

AppSync Navigation
# AWS Glue
Moving data between S3 and DynamoDB into Athena Data Lakes can be made much easier by running Crawlers and Jobs in AWS Glue. Before our new tool however, this was a very cumbersome task in the AWS Console. The underlying API as is typical in AWS-land is top notch. So, really, what it needed was some commandeering of it into our app. Below you can see the four main sections of Glue. Crawlers, Classifiers, Jobs, and Triggers. There will also be a Workflows section that combines the Crawlers and Jobs to make a full fledged ETL process.
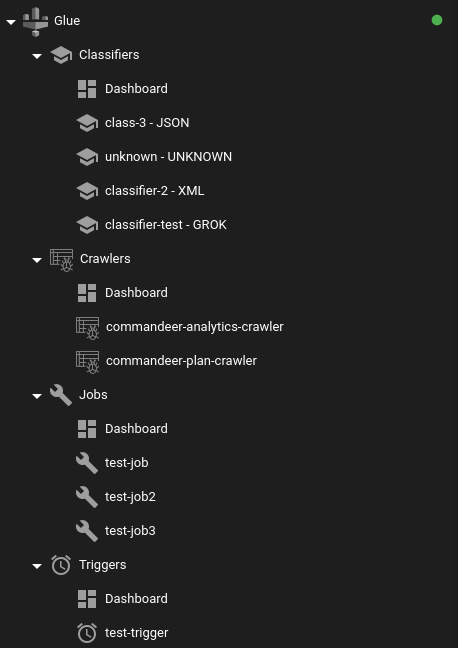
AWS Glue Navigation
# Crawlers
A crawler has a source location such as S3 or DynamoDB and then a destination which is the Athena database. The crawler will run, and produce the correct tables in your database. This is very powerful as you can have all your data setup instantly. For instance, we run this on our S3 data lake analytics data and it automatically creates orur 20 or so tables instantly. Below you can see an example of a crawler that takes the analytics data and saves it to your database..
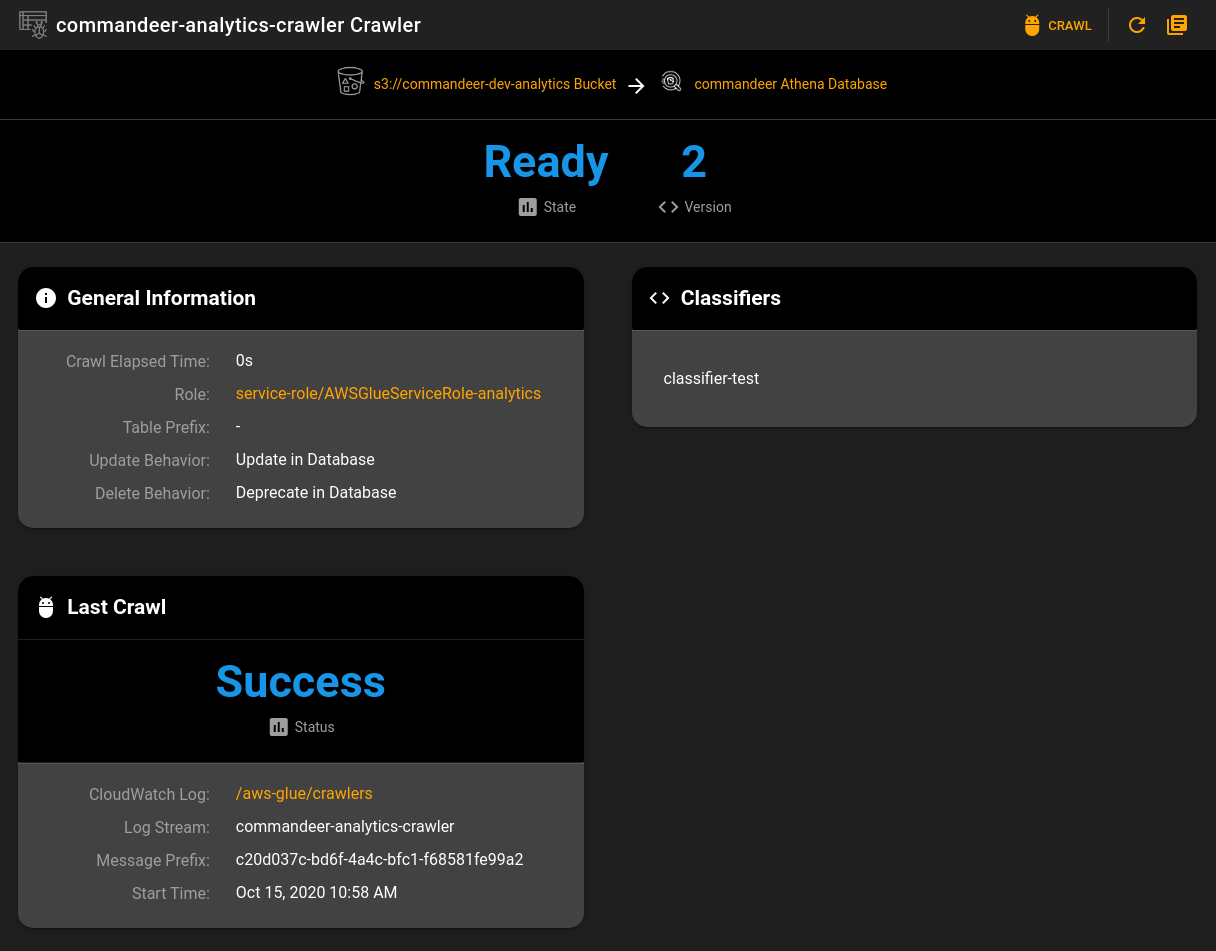
Glue Crawler Detail
The crawlers can also be viewed in the S3 and Dynamo navigation system.
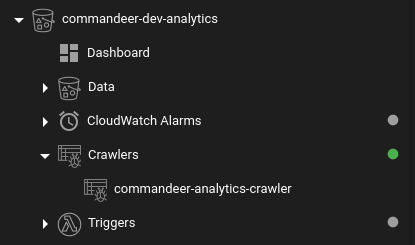
S3 Crawlers
# Jobs
AWS Glue Jobs allow you to run a piece of python or scala code for doing transformations on your data. Below you can see three different jobs that are set to run.

Glue Jobs
# LocalStack
LocalStack allows you to connect to a local mocked version of AWS. We have two new enhancements. The first is that the newer version of LocalStack uses just one edge port to connect to. This greatly simplifies managing it. You can simply set the port on the LocalStack settings.
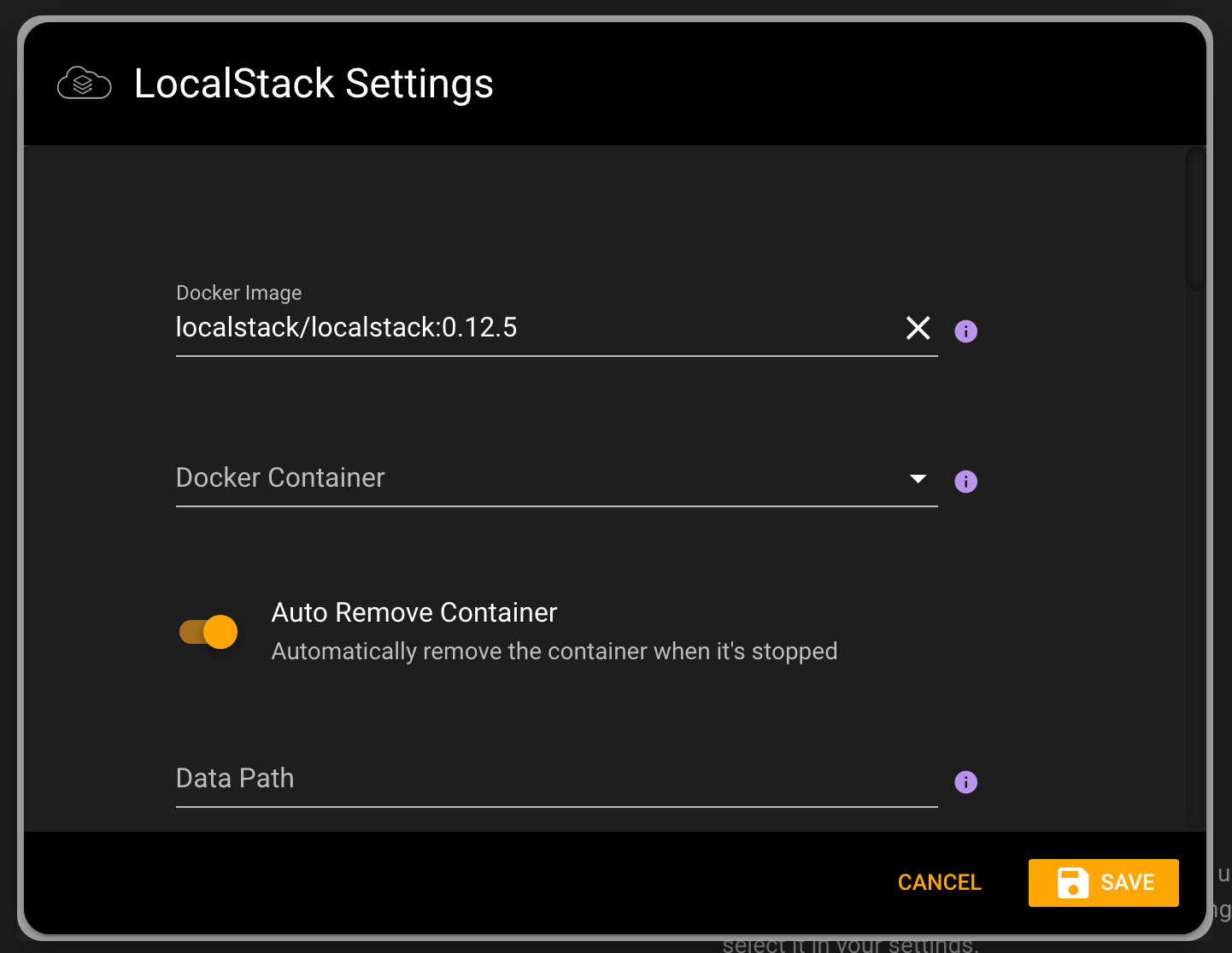
Localstack Url in Settings
We also added a state on the LocalStack page when your current account is not set to local, you will be presented with this message on the LocalStack dashboard. This makes it a bit easier to handle the differences between the local and cloud environments within Commandeer.
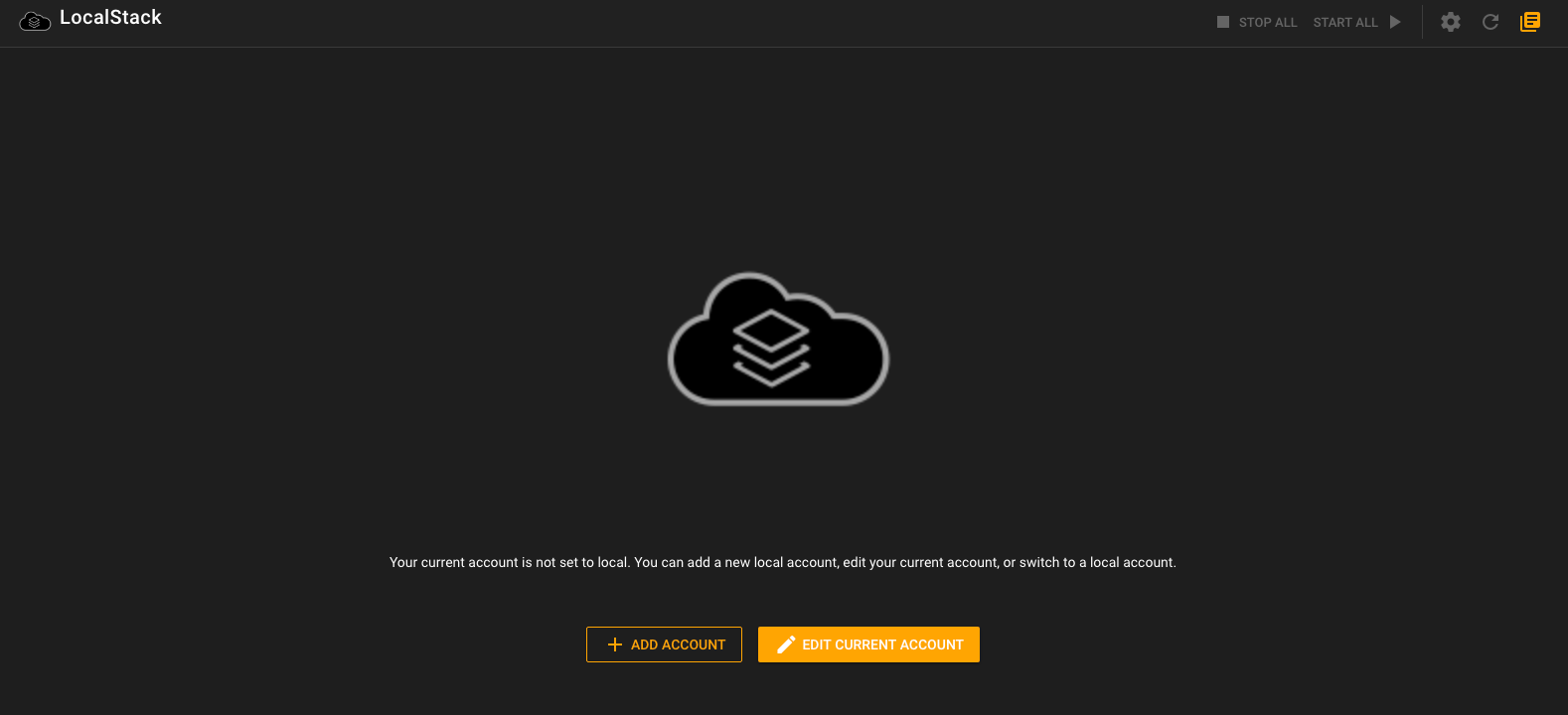
LocalStack state when not connected to a local account
# S3 Treeview Enhancements
In the S3 treeview we are now showing you the CloudWatch Alarms, AWS Glue Crawlers, and Lambda Triggers that can all be connected to an S3 Bucket.
S3 Treeview
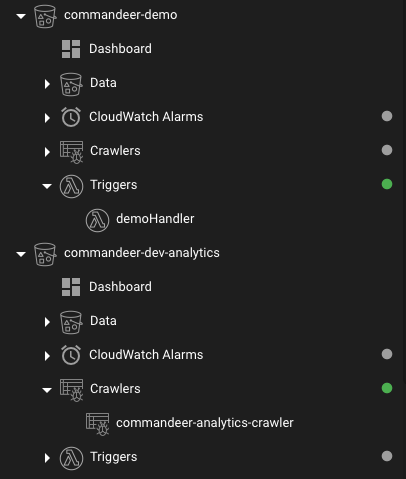
# DynamoDB Treeview Enhancements
In the DynamoDB treeview on the left, you will now find attached CloudWatch Alarms, AWS Glue Crawlers, and DynamoDB Streams that are connected to each table. This helps to quickly see what is connected to your tables.
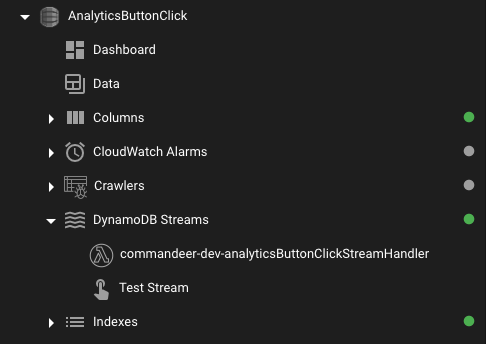
DynamoDB Treeview
# PostgreSQL Updates
We have added the Query History and Favorites to the query runner on PostgresSQL. This works the same way as in Athena, where you can see previous queries, and delete and favorite ones you have run. We also now show you if the query was succcessful and how many records were brought back.
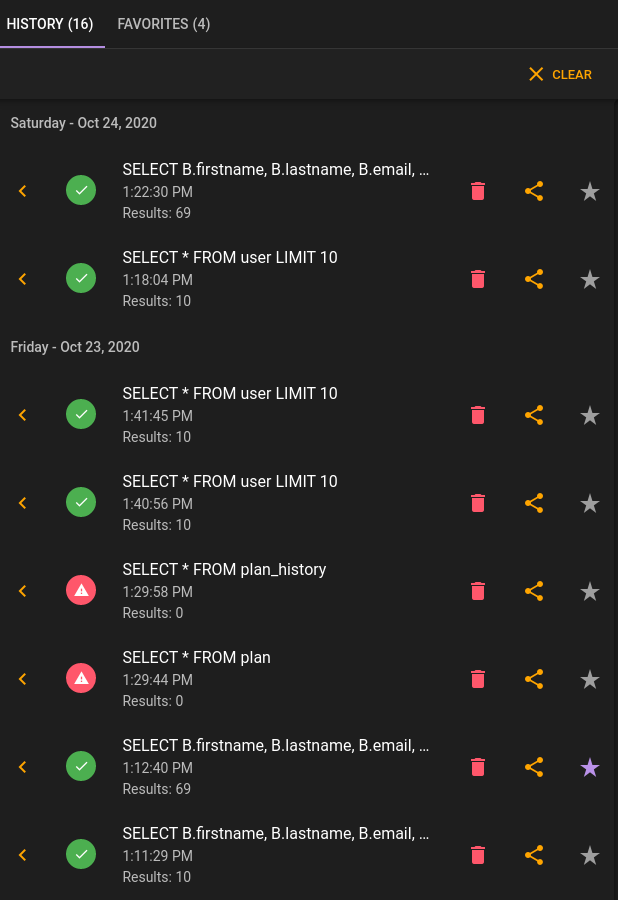
History and Favorites
# Coming Soon
# DynamoDB Query Runner
Currently, you can view data for each of your tables in Dynamo. As we built out the ER Diagram tool for DynamoDB, we noticed that we can really start to infer relationships between tables, and when we look at data in our system, we often want to do joins. For instance, if we are looking at the page views table, we would love to also get back the user inform from the User table. We believe we have the tooling for this ready to go, and are now implementing it. Below you can see an example of the tool. It will allow you to select relationships, and also, view the query in raw JSON, which will help in customizing your queries way easier.
# MySQL and RDS Support
As we continue to focus on data we will be rolling out the MySQL and RDS support in the next couple releases. The interface for MySQL will be much like Athena and Postgres, although without schemas since they are not supported. RDS management will also be coming soon.
# Cognito
We almost have the Cognito service ready to go. Developers managing this tool can soon rejoice!
# Redis
Redis is just about done, we are hoping for a rollout of this as well by December.