Athena - How to build a data lake in 10 minutes
... About 4 min
# Athena - How to build a data lake in 10 minutes - Part 1
Here at Commandeer, we help developers to better manage their serverless and container based systems. Imagine a world where you don't have to pay for your data warehouse. A world that you just pay for very cheap file storage (S3), and only pay when you query that data. Well, that is what Athena offers you. It allows you to save your data into flat files, but then query it with SQL.
In this article I am going to go through how to save your files and setup your tables. In the next month, we will be releasing our full-featured Athena Querying tool, which will allow you to run sql queries, view query history, and create favorite queries. It is going to be one of the most exciting services we have released to date.
# Commandeer Analytics Warehouse
We are building tools at Commandeer based on two things, solving our own pain points in building out serverless and container solutions to problems, but also, we build things based on user usage and feedback. For instance our top three services are S3, DynamoDB, and Lambda. We have continued to provide more and more useful features for these services based on this usage. The second have of this, feedback, is also quite important, so if you have a great idea for accomplishing a repetitive or cumbersome task, drop us a line on our GitHub Issues, and we will prioritize it.
In order to understand system usage, we save analytics on page views, button clicks, account selection and searches into our DynamoDB (nosql) via AppSync (graphql). This provides some great advantages, it scales worldwide, it is fast, and it is dead simple. But, querying DynamoDB for analytics is painful, because you don't get a robust SQL language, you only get their api. It has some good features, but is nowhere near the power of SQL. But, we didn't want to pay a lot for RedShift, or send the data to a Postgres database where we would have to worry about space, etc. We wanted to have a data lake, that is infinitely scaleable, and also practically free. So, we have a Lambda tied to the Analytics tables via a DynamoDB stream, and every time records go into dynamo, we then process them and save them to S3. Below you can see the four different tables, and the corresponding Lambda that is connected to each.

4 DynamoDB tables connected to lambdas
These streams can be configured in a number of different ways, including setting how many records are batched into the lambda, so if you are saving a lot of data, say 1,000 records a minute, you can batch them, so that maybe 100 records at a time can be processed by the Lambda, so you only then pay for 10 lambda invocations.
# Save the data to S3
In order to query Athena data, it must be saved in the correct format. First off, you should save all your data into top level folders in your buckets with names that will correspond to your table names. Below you can see, that we have a large number of tables. The main ones to look at for this example are the 'account-select', 'button-click', 'page-view', and the 'search' folders. (Note: we don't store your actual data from your systems on our servers, we just store generic information, like the fact that you went to the DynamoDB dashboard for instance. This not only helps keep our cost down, because we are not ingesting your data, but also makes the system more secure for you, as your data is not moving into our system.)
The next thing that is important for Athena, is partition keys. Athena is a hive database, and what this really means, is that indexes are the key to the data. While S3 doesn't technically have folders, they allow you to save files using / so you can do things like s3://commandeer-dev-analytics/button-click/partition__date=2020-09-14/data.json. The partition-date is what is called a partition key. This is how Athena is able to intelligently traverse your data. You will want to think hard about your partition keys. For analytics data, doing it by date is ideal. But you might want to also do it by company__id or user_id or have multiple keys.
Below you can see the button-click folder, with partition__date and then user__id as the partition keys, and then the json serde payload.

Drilling down into any of the json files, you can see that is is some very basic data. Just tracking what event took place on the UI, in this case, clicking on a treeview item. Each record of data is its own file.

# Create your Athena Data Lake
Now that data is formed in your S3 bucket, You need to now tell Athena about it. You can write your own SQL to create the tables based on the data in your files, but this is quite laborious. A quicker way is to run an AWS Glue Crawler, which will traverse your s3 bucket, and define your tables automatically. Below you can see a crawler I have already setup that has run, and automatically setup our tables.

Once you run your crawler, it will infer your tables, and let you create them. The actual code for your tables is just DDL, so anyone familiar with SQL is really going to love Athena. Here is an example of the button-click table.
CREATE EXTERNAL TABLE `button_click`(
`id` string COMMENT 'from deserializer',
`name` string COMMENT 'from deserializer',
`label` string COMMENT 'from deserializer',
`userid` string COMMENT 'from deserializer',
`createdat` string COMMENT 'from deserializer')
PARTITIONED BY (
`partition_date` string,
`user_id` string)
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
WITH SERDEPROPERTIES (
'paths'='createdAt,id,label,name,userId')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://commandeer-dev-analytics/button-click/'
TBLPROPERTIES (
'CrawlerSchemaDeserializerVersion'='1.0',
'CrawlerSchemaSerializerVersion'='1.0',
'UPDATED_BY_CRAWLER'='commandeer-analytics-crawler',
'averageRecordSize'='189',
'classification'='json',
'compressionType'='none',
'objectCount'='312',
'recordCount'='312',
'sizeKey'='67495',
'typeOfData'='file')
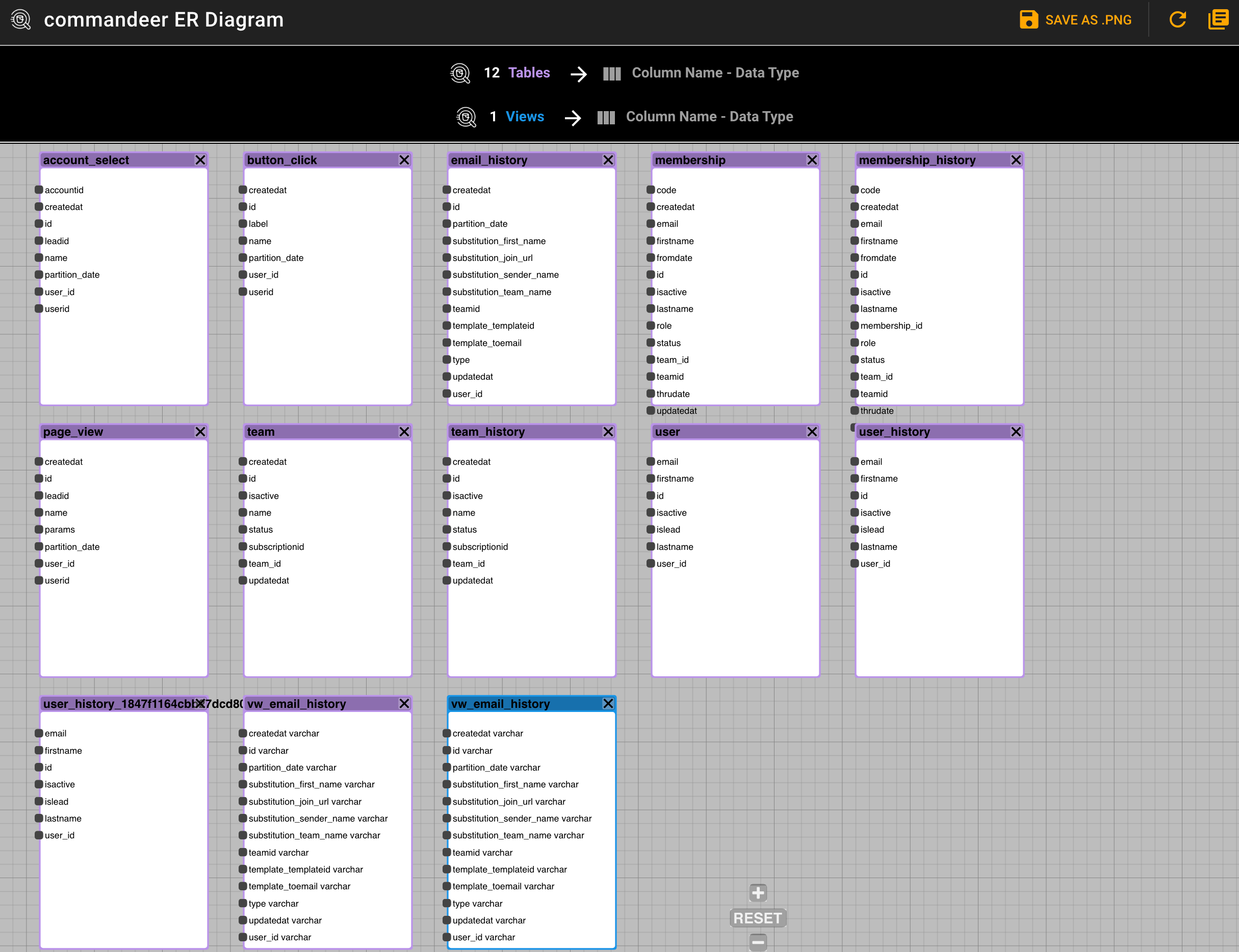
Once this has run, you will now see all your tables. In our case there are 12 tables and 1 view.
# Conclusion
In this blog post, we started saving data into S3, and then ran a crawler to create our tables. This is a really powerful way to get a SQL like experience just with flat files. In the next post, I will break down how to actually query your data, and show in-depth views of how Commandeer let's you manage your data warehouse in a clean and simple GUI.
Until then, happy developing,
Sergeant Serverless